从给处理器加电开始,直到断点为止,程序计数器假设一个值的序列
$$a_0, a_1, …,a_{n-1}$$
其中,每个$a_k$是某个相应的指令$I_k$的地址。每次从$a_k$到$a_{k+1}$的过渡称为 控制转移。这样的控制转移序列叫做处理器的 控制流 。最常见的控制流就是按序执行指令,当然,也有因为if逻辑判断或者while循环而实现的跳转。
除了这些程序本身的代码导致的正常控制流以外,系统也有某种机制可以打断控制流的正常执行,我们把这些突变叫做 异常。异常包括:
- 硬件定时器定期产生的信号
- 数据包到达网络适配器后被放在内存中
- 程序向磁盘请求数据,然后休眠直到数据就绪
- 子进程终止时通知创造这些子进程的父进程
现代操作系统通过使控制流发生突变来对这些情况作出反应。我们常把这些突变叫做异常控制流(Exception Control Flow, ECF)。异常控制流包括了:
- 硬件层中,硬件检测到的事件会触发控制突然转移到异常处理的程序
- 应用层,内核切换上下文来从一个用户进程转移到另一个用户进程
- 应用层,某个进程发送信号到另一个进程,接受者对这个信号进行处理
理解ECF可以帮助我们理清:
- I/O
- 进程
- 虚拟内存
- 应用程序如何与操作系统交互。应用程序通过使用陷阱trap或者系统调用system call的ECF形式,像操作系统请求诸如向磁盘读写数据、从网络读写数据、创建新进程、终止当前进程的服务
- 并发
- 软件异常的原理,如C++, Java, C#中的异常处理原理
异常
异常指的是控制流中的突变因素(不一定是错误)。
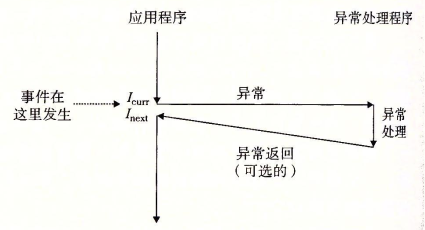
首先是处理器状态,处理器中,状态被编码为不同的位和信号。
处理器状态的变化称为事件。
- 事件可能与当前运行的指令直接相关,比如试图除以0,或者算数溢出
- 当然也可不相关,比如一个I/O请求完成
当处理器检测到有事件发生时,它会查询称为异常表的跳转表,进行一个间接过程调用,到一个专门设计来处理这类事件的操作系统子程序 异常处理程序(exception handler)。
之后异常处理程序就会处理异常。异常处理完后,根据异常的不同类型,可能会:
系统中为所有的异常都分配了一个 唯一的非负整数 异常号。其中:
- 处理器的设计者分配的
- 被零除
- 缺页
- 内存访问违例
- 断点
- 算数运算溢出
- 操作系统内核的设计者分配的
- 系统调用
- 来自外部I/O设备的信号
系统(注意,区别于操作系统)启动的时候,操作系统会分配和初始化一张称为 异常表 的跳转表,条目k包含异常k的 处理程序的地址 。

异常处理程序运行在 内核模式 下,对所有的系统资源都有完全的访问权限。
处理程序处理完事件之后,它执行一条「从中断返回」指令,可选地返回到被中断的程序,并恢复现场,包括把状态弹回到处理器的 控制和数据 寄存器中。如果异常中断的是一个用户程序,会把状态恢复为 用户模式 。
异常的分类
总共四类: 中断(interrupt)、陷阱(trap)、故障(fault)和终止(abort)。
| 类别 | 原因 | 异步/同步 | 返回行为 |
|---|---|---|---|
| 中断 | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
中断
中断是异步发生的,来自 处理器外部 的I/O设备的信号的结果。由于不是由任何一条指令造成的,所以是异步的。
硬件终端的异常处理程序称为 中断处理程序 (interrupt handler)。
在当前指令完成执行之后,处理器会检查中断引脚,如果中断引脚 电压变高 了,就从系统总线读取异常号,然后调用适当的中断处理程序。当处理程序返回之后,处理器会把控制返回给下一条指令,程序继续执行,就好像什么也没发生过一样。
陷阱和系统调用
陷阱是 有意的 异常,它最重要的 用途是 在用户程序和内核之间提供一个像过程一样的接口,叫做 系统调用。
系统调用可能会是:
- 读取一个文件(read)
- 创建一个新的进程(fork)
- 加载一个新的程序(execve)
- 终止当前进程(exit)
为了能够让用于程序访问内核的这些服务,处理器提供了一条特殊的syscall n指令(n为某个服务)。用户程序想要某个服务的时候就执行这个指令,抛出一个 陷阱 到异常处理程序,这个程序会 解析参数 (比如read服务读取文件名),并调用适当的内核程序。当服务执行完之后,控制仍是会返回到下一条指令。所以这是一个同步调用,在read服务执行期间,用户程序会被挂起。
系统调用发生在内核模式中,而普通的函数调用在用户模式中。
C程序用syscall函数可以直接调用任何系统调用,但是标准C库提供了一组方便的包装函数,所以鲜有人会直接用syscall。本书中把这些包装函数叫做 系统级函数 。
在x86-64架构中,所有到Linux系统调用的参数都是通过 寄存器 而不是栈来传递的。一般来说,寄存器%rax包含 系统调用号,%rdi, %rsi, %rdx, %r10, %r8, %r9包含最多6个参数。
看一下我们常见的helloworld,使用系统级函数write。
1 | int main() |
write的第一个参数将输出发送到stdout,第三个参数是要写的字节数。
逆向工程可以得到汇编代码:
1 | .section .data |
故障
故障是由某种错误引起的,他有可能被 故障处理程序 修正。如果被修正了,处理器会把控制返回给 引起故障的指令(不是下一条指令了),重新执行它;如果修复直白,就执行内核中的abort例程,从而终止引起故障的应用程序。
终止
终止是发生了不可修复的致命错误(fatal)时导致的,通常是一些硬件错误。终止处理程序(没错虽然是致命错误,但还会有这个程序)不会把控制返回给应用程序,而是把控制返回给一个abort例程,终止这个应用程序。
进程 process
进程的定义: 一个执行中程序的实例。每个程序都运行在某个进程的 上下文 (context)中。上下文由程序正确运行所需的状态组成。包括:
- 内存中程序的代码和数据
- 栈
- 通用目的寄存器的内容
- 程序计数器
- 环境变量
- 打开文件描述符的集合
逻辑控制流
进程可以提供一种假象,好像它在独占地使用处理器。
多个流并发地执行的一般现象被称为 并发 (concurrencty)。一个进程和其他进程轮流运行的概念被称为 多任务 (multitasking)。一个进程执行它的控制流的一部分的每一时间段叫做 时间片 (time slice)。
并行流(parallel flow):并发流的子集,指两个流并发地运行在不同地处理器核或者计算机上。
私有地址空间
进程可以使程序认为自己正在独占地使用系统地址空间。一般而言,一个进程的私有地址空间是无法被另一个进程访问到的。
每个私有地址空间都有着相似的结构。
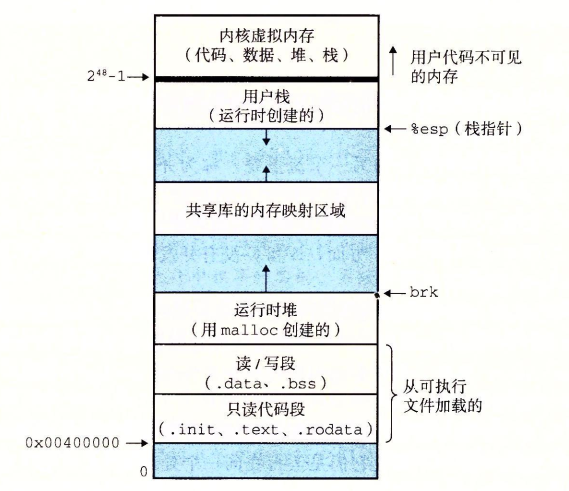
用户模式和内存模式
模式位(mode bit):一个寄存器,描述了进程当前的权限。当模式位为1时,进程运行在内核模式中,否则运行在用户模式中。当进程运行在 内核模式中时,可以执行指令集中的任何指令,并且可以访问系统中的任何内存位置。当进程处于 用户模式下时,进程不允许执行特权指令,比如停职处理器、改变模式位、发起一个IO操作,也不允许进程直接引用地址空间中内核区内的代码和数据(否则会引起fatal)。
从用户模式切换为内核模式的唯一方法是通过诸如中断、故障或者陷阱这样的异常。发生异常时,控制传递到异常处理程序,处理器将模式从用户模式变为内核模式。
上下文切换
内核为每个进程维持一个上下文。 上下文 是内核重新启动一个被抢占的进程所需的状态,包括:
- 通用目的寄存器
- 浮点寄存器
- 程序计数器
- 用户占
- 状态寄存器
- 内核栈
- 内核数据结构
- 描述控件地址的页表
- 包含当前进程信息的进程表
- 包含进程已打开文件的信息的文件表
调度器会做一种叫做调度的决策,在程序执行的某个时刻,内核决定抢占当前进程并重新开始一个之前被抢占了的进程。当内核选择一个新的进程运行时,内核 调度 了这个进程。调度的时候,内核执行 上下文切换 机制,保存当前进程的上下文,恢复新进程的上下文,然后把控制交给新的进程。
发生上下文切换的时机有很多种,比如系统调用(陷阱)(read等IO操作)、sleep系统调用(显式请求调用进程休眠)、中断。
所有的系统都有某种产生周期性定时器中断的机制,每隔1或者10毫秒。发证定时器中断的时候,内核就有可能进行一次调度。
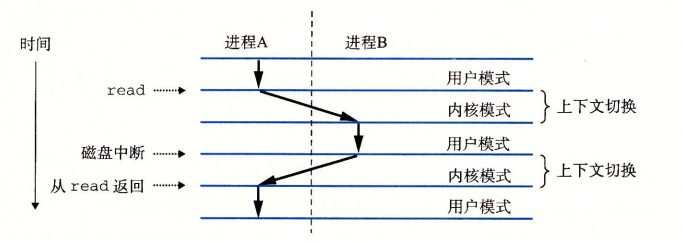
错误包装函数
做系统调用的时候,我们最好是判断其返回值。但是如果频繁判断返回值,会让代码变得很冗余。所以本书提出在自己的应用中对系统调用做一层封装,比如你的逻辑是foo,那就首字母大写做一个Foo,包装对错误的处理。比如:
1 | pid_t Fork(void) |
对进程的控制
获取进程ID
每个进程都有一个唯一的正数进程ID(PID)。
getpid函数返回调用进程的PID。getppid函数返回它的父进程的PID。
1 |
|
创建和终止进程
进程总是处于以下 三种状态 之一:
- 运行
- 在CPU上执行
- 等待被执行,最终会被内核调度到
- 停止 进程的执行被 挂起(suspended),且不会被调度到。当收到SIGSTOP\SIGTSTP\SIGTTIN\TIGTTOU信号时,进程会被停止,直到它收到一个SIGCOUNT信号,才会再次运行
- 终止 进程永远终止了。进程可能因为三种原因被终止:
- 收到一个信号,这个信号的默认行为是终止进程
- 从主程序返回
- 调用exit函数
父进程 通过fork函数创建一个新的运行的子进程。
fork的意思是创建一个几乎与父进程相同的子进程,最大的区别在于它们拥有不同的PID而已。子进程得到和父进程用户级虚拟地址空间相同但独立的一份 副本 ,包括代码、数据段、堆、共享库和用户栈。自己进程还获得与父进程任何打开文件描述符相同的文件,子进程可以读写父进程中打开的任何文件。
当启动fork函数的时候,会在父进程返回子进程的PID,在子进程则返回0,代表自己是被启动的子进程。
1 | int main() |
如上的代码,我们可以用pid是否为0来判断逻辑是否运行在子进程中。由于子进程的数据是一份副本,所以子进程对变量x的改动并不会影响父进程中x的值。
最终打印出:
1 | parent: x=0 |
注意,由于子进程和父进程是并发地执行,所以不能保证哪一个先执行到,也即不能保证这两句print的顺序。
提问:为什么能够看到父进程和子进程打印在 同一个屏幕中 呢?
这是因为父进程和子进程共享同一个打开文件stdout,也就是对应到屏幕上那个输出文件。
易混点:下面的程序代码运行后,总共有多少个进程?
1 | int main() |
答案是4个。如图:
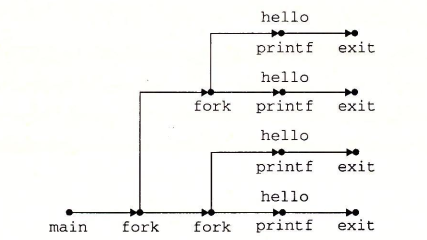
子进程回收
当子进程终止的时候,并不会马上被内核从系统中清除,而是会进入一种已终止的状态,知道被它的父进程回收。一个处于已终止状态的进程被称为 僵尸进程 (zombie)。僵尸进程虽然没有运行,但是仍会消耗系统的内存资源。
父进程回收已经终止的子进程的时候,内核会将子进程的退出状态传递给父进程,然后抛弃子进程。
init进程的PID是1,它是在系统启动时被内核创建的,为一切进程的祖先。如果父进程还没有回收它的僵尸子进程就终止了,那么内核会安排init进程去回收他们。
一个进程可以通过waitpid函数来等待它的子进程终止或停止。
1 |
|
waitpid会挂起调用进程的执行(阻塞),直到它的等待集合中的一个子进程终止。
当pid大于零时,代表某一个具体的子进程,当它等于-1时代表父进程所有的子进程。
进程休眠
sleep可以将进程挂起一段时间。
1 |
|
pause函数可以让调用函数休眠,直到该进程 收到一个信号。
加载和运行程序
execve在当前进程的上下文中加载并运行一个新程序。
1 |
|
加载并运行可执行目标文件filename。execve调用一次且从不返回。(相比之下fork调用一次返回两次)
后面两个参数分别是新程序main函数的参数以及环境变量。
环境变量需要先被设置,最后传给main的只是环境变量的名字。
设置和取出环境变量:
1 |
|
fork会运行一个新的子进程。execve函数在当前进程的上下文加载并运行一个新的程序。它会覆盖当前进程的地址空间,但没有创建一个新的进程,新的程序仍拥有 相同的PID ,而且继承了调用了execve函数时已经打开的所有文件描述符。
信号
作用:允许进程和内核中断其他进程。
每种信号类型都对应于某种系统事件。
传送一个信号到目的进程有两个步骤:
- 发送信号 可能有两种原因:
- 内核检测到一个系统事件,比如除零错误或者子进程终止
- 一个进程调用了kill函数,显示地要求内核发送一个信号给目的进程
- 接收信号 目的进程被内核强迫以某种方式对信号的发送做出反应。进程可以忽略该信号,终止或者执行 信号处理程序。
待处理信号:发出而没有被接收的信号。
阻塞某种类型的信号。一旦被阻塞,虽然信号还是可以被发出来,但是不会被接收,直到取消阻塞。
内核为每个进程在pending位向量中维护者待处理信号的集合,在blocked位向量中维护被阻塞的信号集合。
发送信号
Unix系统中向进程发送信号的机制都是基于 进程组(process group)的。
进程组
一般而言,子进程和它的父进程属于同一个进程组。
1 |
|
可以使用setpgid来改变某个进程的进程组。
1 | int setpgid(pid_t pid, pid_t pgid) |
kill发送信号
使用/bin/kill可以给某个进程或者进程组发送 任意的 信号。当pid为负数时,代表进程组。
1 | // 发送信号9给进程15213 |
从键盘发送信号
按下ctrl+c或者ctrl+z的时候是发送信号给整个信号组。
用kill函数发送信号
1 |
|
当pid为正数,代表某个进程;当为0时,代表本进程所在进程组中的所有进程(包括自己);当为负数时,其绝对值代表着某个进程组。
用alarm函数发送信号
进程通过alram函数向他自己发送SIGALRM信号。
1 |
|

